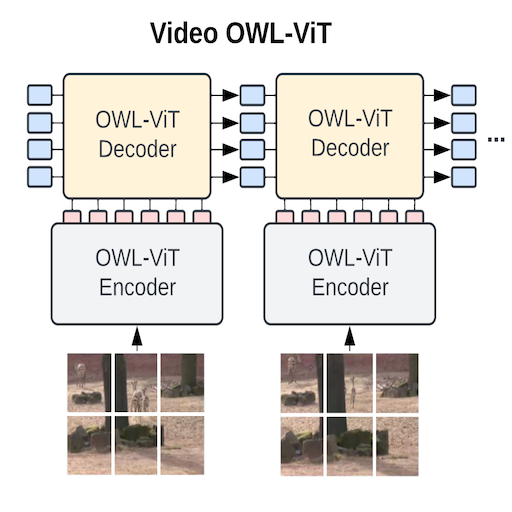
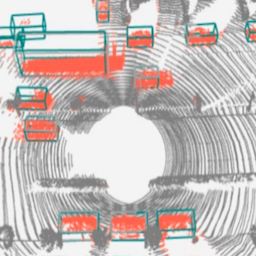
RSN: Range Sparse Net for Efficient, Accurate LiDAR 3D Object Detection
Range Sparse Net (RSN) is a simple, efficient, and accurate 3D object framework for real time detection using LiDAR with extensive range. Lightweight 2D convolutions on dense range images results in significantly fewer selected foreground points, thus enabling the later sparse convolutions in RSN to efficiently operate. RSN runs at more than 60 frames per second on a 150mx150m detection region on Waymo Open Dataset (WOD) while being more accurate than previously published detectors.
@InProceedings{Sun_2021_CVPR,
author = {Sun, Pei and Wang, Weiyue and Chai, Yuning and Elsayed, Gamaleldin and Bewley, Alex and Zhang, Xiao and Sminchisescu, Cristian and Anguelov, Dragomir},
title = {RSN: Range Sparse Net for Efficient, Accurate LiDAR 3D Object Detection},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {5725-5734}
}